源代码仓库:CompilePrincipleLearning/experiment_2 · yusixian/CompilePrincipleLearning (github.com)
# 一。实验目的
- 掌握 LL (1) 分析法的基本原理
- 掌握 LL (1) 分析表的构造方法
- 掌握 LL (1) 驱动程序的构造方法
# 二。实验内容及要求
编写识别单词的词法分析程序。
根据某一文法编制调试 LL(1)分析程序,以便对任意输入的符号串进行分析。本次实验的目的主要是加深对预测分析 LL(1)分析法的理解。
例:对下列文法,用 LL(1)分析法对任意输入的符号串进行分析:
(1)E->TG
(2)G->+TG|—TG
(3)G->ε
(4)T->FS
(5)S->*FS|/FS
(6)S->ε
(7)F->(E)
(8)F->i
输出的格式如下:
(1) LL(1)分析程序,编制人:姓名,学号,班级
(2) 输入一以 #结束的符号串 (包括 +*()i# ):i*(i+i)+(i*i)#
(3) 输出过程步骤如下:
| 步骤 | 分析栈 | 剩余输入串 | 所用产生式 |
|---|---|---|---|
| 1 | E | i+i*i# | E->TG |
(4) 输入符号串为非法符号串 (或者为合法符号串)
备注:
(1) 在 “ 所用产生式 ” 一列中如果对应有推导则写出所用产生式;如果为匹配终结符则写明匹配的终结符;如分析异常出错则写为 “分析出错”;若成功结束则写为 “分析成功”。
(2) 在此位置输入符号串为用户自行输入的符号串。
(3) 上述描述的输出过程只是其中一部分的。
注意:1.表达式中允许使用运算符(+-*/)、分割符(括号)、字符 i,结束符 #;
2.如果遇到错误的表达式,应输出错误提示信息(该信息越详细越好);
3.对学有余力的同学,测试用的表达式事先放在文本文件中,一行存放一个表达式,同时以分号分割。同时将预期的输出结果写在另一个文本文件中,以便和输出进行对照;
4.可采用的其它的文法
# 三。实验过程
# 1、采用的数据结构
产生式类型定义为 type,左侧为 origin,大写字符,右侧产生的字符
struct type { /* 产生式类型定义 */ | |
char origin; /* 产生式左侧字符 大写字符 */ | |
string array; /* 产生式右边字符 */ | |
int length; /* 字符个数 */ | |
type():origin('N'), array(""), length(0) {} | |
void init(char a, string b) { | |
origin = a; | |
array = b; | |
length = array.length(); | |
} | |
}; |
初始化数据结构如下:
e.init('E', "TG"), t.init('T', "FS"); | |
g.init('G', "+TG"), g1.init('G', "^"); | |
s.init('S', "*FS"), s1.init('S', "^"); | |
f.init('F', "(E)"), f1.init('F', "i"); |
# 2、头文件声明和全局变量定义
如下
#include <iostream> | |
#include <string> | |
#include <fstream> | |
#include <vector> | |
#include <cstring> | |
using namespace std; | |
const string ExpFileName = "./exp.txt"; | |
char analyeStack[20]; /* 分析栈 */ | |
char restStack[20]; /* 剩余栈 */ | |
const string v1 = "i+*()#"; /* 终结符 */ | |
const string v2 = "EGTSF"; /* 非终结符 */ | |
const string acceptStr = "i+*()#"; // 接受的字符串 | |
int top, ridx, len; /*len 为输入串长度 */ | |
struct type { /* 产生式类型定义 */ | |
char origin; /* 产生式左侧字符 大写字符 */ | |
string array; /* 产生式右边字符 */ | |
int length; /* 字符个数 */ | |
type():origin('N'), array(""), length(0) {} | |
void init(char a, string b) { | |
origin = a; | |
array = b; | |
length = array.length(); | |
} | |
}; | |
type e, t, g, g1, s, s1, f, f1; /* 产生式结构体变量 */ | |
type C[10][10]; /* 预测分析表 */ |
# 4、函数汇总
# (1)函数汇总表
| 函数名称 | 功能简述 |
|---|---|
readFile | 读取文件函数,返回一个 string 动态数组,以行数分割 |
init | 初始化函数,在该函数中进行分析栈、剩余栈的初始化 |
print | 输出当前分析栈和剩余栈 |
isTerminator | 判断当前字符 c 是否是终结符 |
analyze | 分析字符串 s,输出其分析步骤 |
main | 主程序入口,从此进入,填充初始分析表及产生式初始化,调用读取文件函数开始分析 |
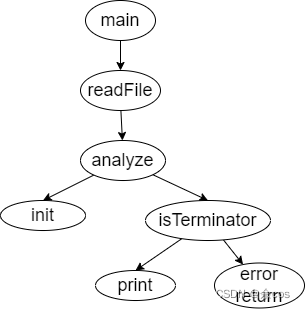
# (2)函数的调用关系
# 5、实验结果
# 输入
文件 exp.txt
i*(i+i)+(i*i)# | |
i*i-i/1# | |
i+i*i+i*(i+i*i)# | |
i+*i(i)+i(i+i*i)# | |
i+i(i)#code.txt |
# 输出
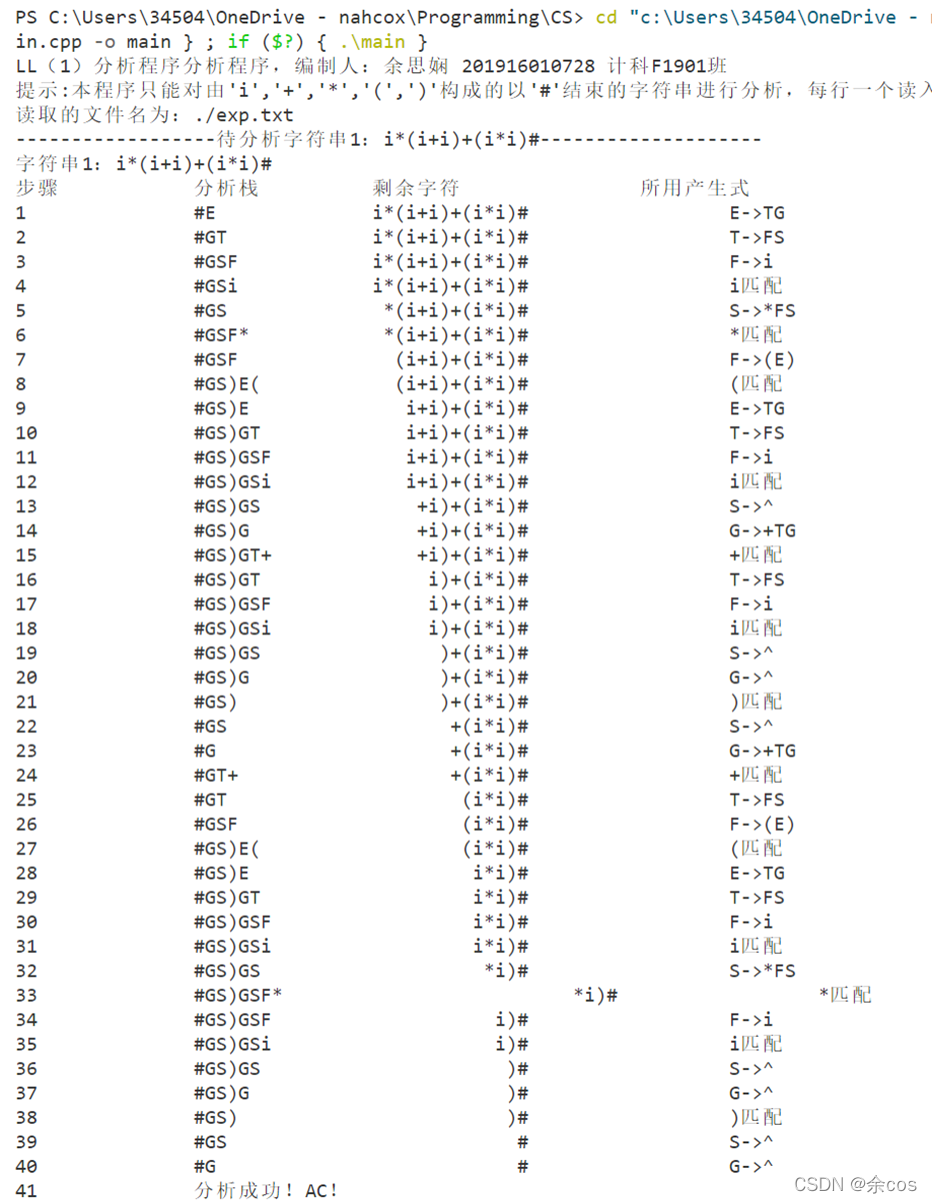
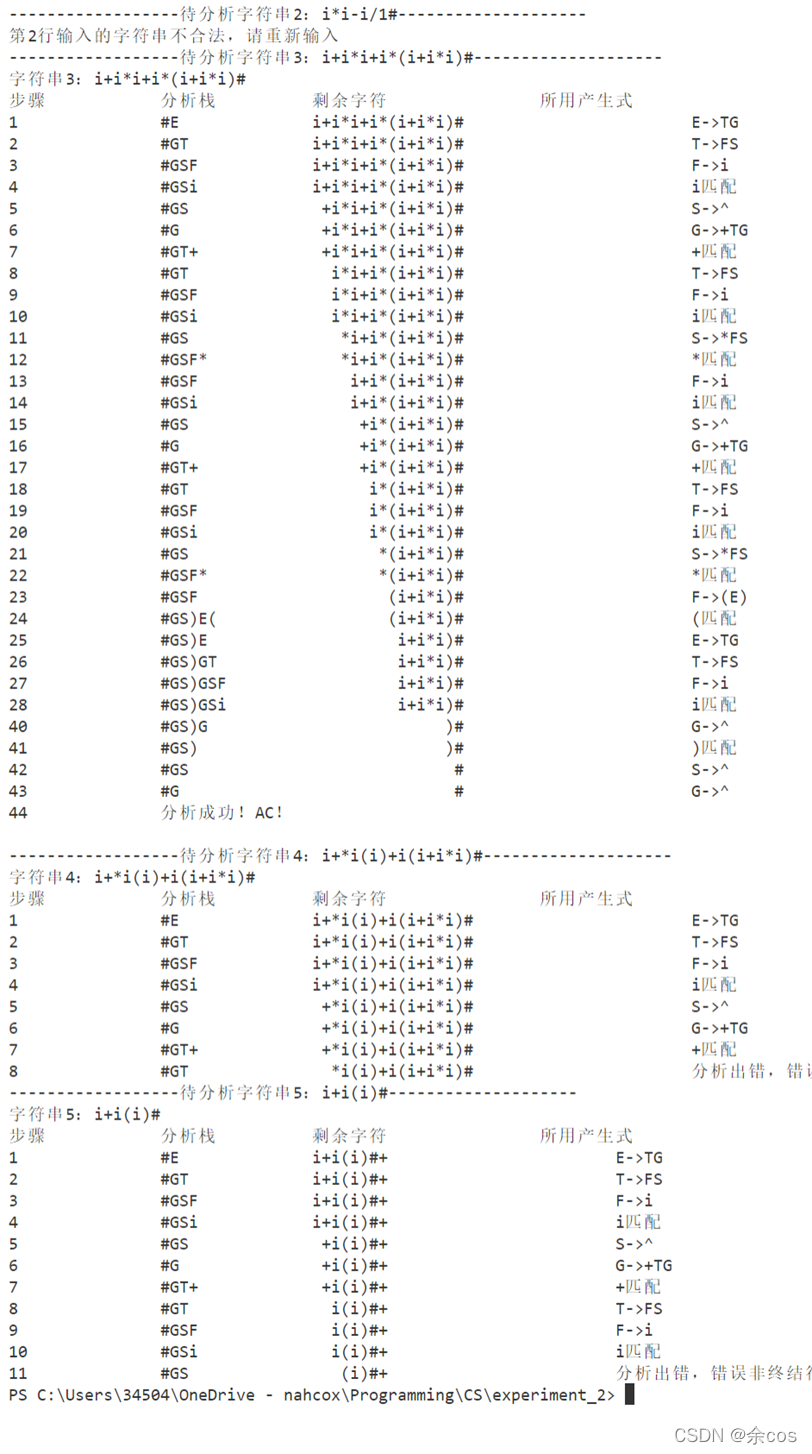
# 完整代码
/* | |
* @Author: cos | |
* @Date: 2022-04-12 23:03:36 | |
* @LastEditTime: 2022-04-13 01:32:58 | |
* @LastEditors: cos | |
* @Description: | |
* @FilePath: \CS\experiment_2\main.cpp | |
*/ | |
#include <iostream> | |
#include <string> | |
#include <fstream> | |
#include <vector> | |
#include <cstring> | |
using namespace std; | |
const string ExpFileName = "./exp.txt"; | |
char analyeStack[20]; /* 分析栈 */ | |
char restStack[20]; /* 剩余栈 */ | |
const string v1 = "i+*()#"; /* 终结符 */ | |
const string v2 = "EGTSF"; /* 非终结符 */ | |
int top, ridx, len; /*len 为输入串长度 */ | |
struct type { /* 产生式类型定义 */ | |
char origin; /* 产生式左侧字符 大写字符 */ | |
string array; /* 产生式右边字符 */ | |
int length; /* 字符个数 */ | |
type():origin('N'), array(""), length(0) {} | |
void init(char a, string b) { | |
origin = a; | |
array = b; | |
length = array.length(); | |
} | |
}; | |
type e, t, g, g1, s, s1, f, f1; /* 产生式结构体变量 */ | |
type C[10][10]; /* 预测分析表 */ | |
void print() {/* 输出分析栈和剩余栈 */ | |
for(int i = 0; i <= top + 1; ++i) /* 输出分析栈 */ | |
cout << analyeStack[i]; | |
cout << "\t\t"; | |
for(int i = 0; i < ridx; ++i) /* 输出对齐符 */ | |
cout << ' '; | |
for(int i = ridx; i <= len; ++i) /* 输出剩余串 */ | |
cout << restStack[i]; | |
cout << "\t\t\t"; | |
} | |
// 读文件 | |
vector<string> readFile(string fileName) { | |
vector<string> res; | |
try { | |
ifstream fin; | |
fin.open(fileName); | |
string temp; | |
while (getline(fin, temp)) | |
res.push_back(temp); | |
return res; | |
} catch(const exception& e) { | |
cerr << e.what() << '\n'; | |
return res; | |
} | |
} | |
bool isTerminator(char c) { // 判断是否是终结符 | |
return v1.find(c) != string::npos; | |
} | |
void init(string exp) { | |
top = ridx = 0; | |
len = exp.length(); /* 分析串长度 */ | |
for(int i = 0; i < len; ++i) | |
restStack[i] = exp[i]; | |
} | |
void analyze(string exp) { // 分析一个文法 | |
init(exp); | |
int k = 0; | |
analyeStack[top] = '#'; | |
analyeStack[++top] = 'E'; /*'#','E' 进栈 */ | |
cout << "步骤\t\t分析栈 \t\t剩余字符 \t\t所用产生式 " << endl; | |
while(true) { | |
char ch = restStack[ridx]; | |
char x = analyeStack[top--]; /*x 为当前栈顶字符 */ | |
cout << ++k << "\t\t"; | |
if(x == '#') { | |
cout << "分析成功!AC!\n" << endl; /* 接受 */ | |
return; | |
} | |
if(isTerminator(x)) { | |
if (x == ch) { // 匹配上了 | |
print(); | |
cout << ch << "匹配" << endl; | |
ch = restStack[++ridx]; /* 下一个输入字符 */ | |
} else { /* 出错处理 */ | |
print(); | |
cout << "分析出错,错误终结符为" << ch << endl; /* 输出出错终结符 */ | |
return; | |
} | |
} else { /* 非终结符处理 */ | |
int m, n; // 非终结符下标, 终结符下标 | |
v2.find(x) != string::npos ? m = v2.find(x) : -1; //m 为 - 1 则说明找不到该非终结符,出错 | |
v1.find(ch) != string::npos ? n = v1.find(ch) : -1; //n 为 - 1 则说明找不到该终结符,出错 | |
if(m == -1 || n == -1) { /* 出错处理 */ | |
print(); | |
cout << "分析出错,错误非终结符为" << x << endl; /* 输出出错非终结符 */ | |
return; | |
} | |
type nowType = C[m][n];/* 用来接受 C [m][n]*/ | |
if(nowType.origin != 'N') {/* 判断是否为空 */ | |
print(); | |
cout << nowType.origin << "->" << nowType.array << endl; /* 输出产生式 */ | |
for (int j = (nowType.length - 1); j >= 0; --j) /* 产生式逆序入栈 */ | |
analyeStack[++top] = nowType.array[j]; | |
if (analyeStack[top] == '^') /* 为空则不进栈 */ | |
top--; | |
} else { /* 出错处理 */ | |
print(); | |
cout << "分析出错,错误非终结符为" << x << endl; /* 输出出错非终结符 */ | |
return; | |
} | |
} | |
} | |
} | |
int main() { | |
e.init('E', "TG"), t.init('T', "FS"); | |
g.init('G', "+TG"), g1.init('G', "^"); | |
s.init('S', "*FS"), s1.init('S', "^"); | |
f.init('F', "(E)"), f1.init('F', "i"); /* 结构体变量 */ | |
/* 填充分析表 */ | |
C[0][0] = C[0][3] = e; | |
C[1][1] = g; | |
C[1][4] = C[1][5] = g1; | |
C[2][0] = C[2][3] = t; | |
C[3][2] = s; | |
C[3][4] = C[3][5] = C[3][1] = s1; | |
C[4][0] = f1; C[4][3] = f; | |
cout << "LL(1)分析程序分析程序,编制人:xxx xxx 计科xxxx班" << endl; | |
cout << "提示:本程序只能对由'i','+','*','(',')'构成的以'#'结束的字符串进行分析,每行一个读入的字符串" << endl; | |
cout << "读取的文件名为:" << ExpFileName << endl; | |
vector<string> exps = readFile(ExpFileName); | |
int len = exps.size(); | |
for(int i = 0; i < len; i++) { | |
string exp = exps[i]; | |
cout << "------------------待分析字符串" << i+1 << ":"<< exp << "--------------------" << endl; | |
bool flag = true; | |
for(int j = 0; j < exp.length(); j++) { | |
if(!isTerminator(exp[j])) { | |
cout << "第"<< i+1 << "行输入的字符串不合法,请重新输入" << endl; | |
flag = false; | |
break; | |
} | |
} | |
if(flag) { | |
cout << "字符串" << i+1 << ":" << exp << endl; | |
analyze(exp); | |
} | |
} | |
return 0; | |
} |